
C/C++中的动态分配的内存需要我们手动释放,经常会忘记释放内存,导致内存泄漏。所以很多现代语言都加上了垃圾回收机制。变量的分配在栈上还是堆上不是由new/malloc决定,而是通过编译器的“逃逸分析”来决定
前置知识
堆与栈
在计算机领域,堆栈是一个不容忽视的概念,堆栈是一种数据结构。堆栈都是一种数据项按序排列的数据结构,只能在一端(称为栈顶(top))对数据项进行插入和删除。在单片机应用中,堆栈是个特殊的存储区,主要功能是暂时存放数据和地址,通常用来保护断点和现场。
栈
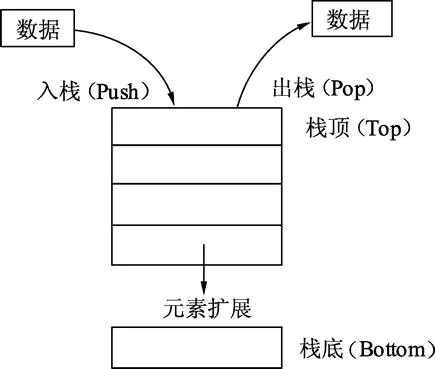
栈的操作及扩展
堆
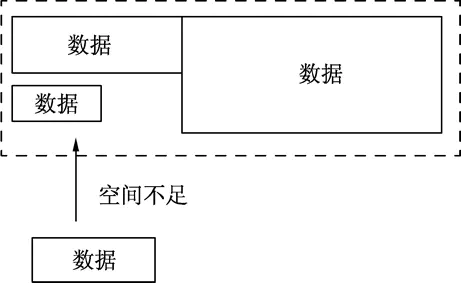
堆分配内存和栈分配内存相比,堆适合不可预知大小的内存分配。但是为此付出的代价是分配速度较慢,而且会形成内存碎片。
什么是逃逸分析
在编译程序优化理论中,逃逸分析是一种确定指针动态范围的方法——分析程序的哪些地方可以访问到指针。
常见的两种逃逸情景:
-
函数中局部对象指针被返回
-
对象指针被多个子程序(线程、协程)共享使用
为什么做逃逸分析
如果变量都分配到堆上,堆不像栈可以自动清理。它会引起Go频繁地进行垃圾回收,而垃圾回收会占用比较大的系统开销(占用CPU容量的25%)。
说白了就是通过逃逸分析,可以尽量把那些不需要分配到堆上的变量直接分配到栈上,堆上的变量少了,会减轻分配堆内存的开销,同时也会减少gc的压力,提高程序的运行速度。
逃逸场景
指针逃逸
package main
type Team struct {
Name string
Num int
}
func TeamRegister(name string, num int) *Team {
s := new(Team)
s.Name = name
s.Num = num
return s
}
func main() {
TeamRegister("Warrior", 18)
}
函数 TeamRegister() 内部 s 为局部变量,其值通过函数返回值返回,s 本身为一指针,其指向的内存地址不会是栈而是堆。通过运行命令查看逃逸分析日志
% go build -gcflags=-m escape_1.go
# command-line-arguments
./escape_1.go:8:6: can inline TeamRegister
./escape_1.go:18:6: can inline main
./escape_1.go:19:14: inlining call to TeamRegister
./escape_1.go:8:19: leaking param: name
./escape_1.go:9:10: new(Team) escapes to heap
./escape_1.go:19:14: new(Team) does not escape
栈空间不足逃逸(空间开辟过大)
package main
func Slice() {
s := make([]int, 10000, 10000)
for index, _ := range s {
s[index] = index
}
}
func main() {
Slice()
}
函数Slice()分配切片长度为1000时并没有发生逃逸,当分配切片长度为10000就发生了逃逸。当栈空间不足以存放当前对象时或无法判断当前切片长度时会将对象分配到堆中。
通过终端运行逃逸日志查看
% go build -gcflags=-m escape_2.go
# command-line-arguments
./escape_2.go:3:6: can inline Slice
./escape_2.go:10:6: can inline main
./escape_2.go:11:7: inlining call to Slice
./escape_2.go:4:11: make([]int, 10000, 10000) escapes to heap
./escape_2.go:11:7: make([]int, 10000, 10000) escapes to heap
动态类型逃逸(不确定长度大小)
很多函数参数为interface类型,比如fmt.Println(a …interface{}),编译期间很难确定其参数的具体类型,也能产生逃逸。
package main
import "fmt"
func main() {
s := "Escape"
fmt.Println(s)
}
% go build -gcflags=-m escape_3.go
# command-line-arguments
./escape_3.go:7:13: inlining call to fmt.Println
./escape_3.go:7:13: ... argument does not escape
./escape_3.go:7:13: s escapes to heap
闭包引用对象逃逸
package main
import "fmt"
func series() func() int {
a, b := 0, 1
return func() int {
a, b = b, a+b
return a
}
}
func main() {
f := series()
for i := 0; i < 10; i++ {
fmt.Printf("Series:%d\n", f())
}
}
% go build -gcflags=-m escape_4.go
# command-line-arguments
./escape_4.go:5:6: can inline series
./escape_4.go:7:9: can inline series.func1
./escape_4.go:14:13: inlining call to series
./escape_4.go:7:9: can inline main.func1
./escape_4.go:16:30: inlining call to main.func1
./escape_4.go:16:13: inlining call to fmt.Printf
./escape_4.go:6:2: moved to heap: a
./escape_4.go:6:5: moved to heap: b
./escape_4.go:7:9: func literal escapes to heap
./escape_4.go:14:13: func literal does not escape
./escape_4.go:16:13: ... argument does not escape
./escape_4.go:16:30: ~R0 escapes to heap
逃逸总结:
-
栈上分配内存比在堆中分配内存有更高的效率
-
栈上分配的内存不需要GC处理
-
堆上分配的内存使用完毕会交给GC处理
-
逃逸分析目的是决定内分配地址是栈还是堆
-
逃逸分析在编译阶段完成
编译器觉得变量应该分配在堆和栈上的原则是:
-
变量是否被取地址;
-
变量是否发生逃逸。